Thanks to COVID, Halloween is weird this year. A ‘touchless’ remote candy delivery system was in order. Due to some misunderstandings about whether the system would be appreciated, it became a very 11th hour project. I started around 1PM Halloween for a 3:30 Trick-or-Treat start time. I missed by 45 minutes. Could have been worse.
Thanks to COVID, Halloween is weird this year. A ‘touchless’ remote candy delivery system was in order. Due to some misunderstandings about whether the system would be appreciated, it became a very 11th hour project. I started around 1PM Halloween for a 3:30 Trick-or-Treat start time. I missed by 45 minutes. Could have been worse.
Boo Boy
 We happened to have a really cute Halloween decoration a friend of Lauren’s had given us many years ago. He’s stood in a plastic bag all these years – just waiting to be called on. Today was the day. He was going to get to hold up the output end of the remote delivery pipe. Some assembly required.
We happened to have a really cute Halloween decoration a friend of Lauren’s had given us many years ago. He’s stood in a plastic bag all these years – just waiting to be called on. Today was the day. He was going to get to hold up the output end of the remote delivery pipe. Some assembly required.
PVC to the rescue
Do we have anything that would serve as the delivery device? Laur had seen a woman strapping some flexible corrugated tubing to a banister for this purpose. Corrugated is sub-optimal if you want things to slide smoothly through the tube. But there in the basement ceiling was a piece of 2″ PVC pipe. That would do. (There’s lots of 1.5″ pipe, for emergency sump piping, but that’s a little too small.)
The doorbell problem
Even if I could get Boo Boy to hold one end of the pipe securely and the house to hold the other, a showstopper was the doorbell: If a Trick or Treater had to come right up to the door to ring the doorbell, it kind of defeated the ‘remote’ part of things.
To keep the kid at a distance, she’d need to be able to ring the doorbell from in front of the front steps. And in addition to making noise inside, the button and mounting would need to be mechanically robust enough for kids to hit and not break. Yeah, I could certainly invent a way to do that, but it would add to the project. That was part of what put the project on hold.
After some other misunderstandings were cleared up, I decided I could figure out something to do about the doorbell, and I could start construction. Unfortunately, Trick-or-Treat hours started in a couple of hours. Better hurry.
Construction
Boo Boy arm
 By design, Boo Boy didn’t have visible arms. But his torso was a piece of wood and hidden under the sheet, so attaching an arm should be easy. First tries were too long, but cutting it down and reattaching was easy.
By design, Boo Boy didn’t have visible arms. But his torso was a piece of wood and hidden under the sheet, so attaching an arm should be easy. First tries were too long, but cutting it down and reattaching was easy.
The bandsaw cut a roundish notch for the pipe. The ideal way to attach the pipe to his arm/hand would have been a zip tie thru the sheet, but I didn’t want to damage anything. I just bunched his sheet up behind the arm and hooked a zip tie around a screw on the bottom. Worked out acceptably.
Boo Boy stand
I’d found a screw in the screen door frame that should provide fairly sound mounting in all directions, as well as locating the pipe high enough for a good slope. But while Boo Boy could stand OK, and could provide good vertical support for the pipe, he couldn’t guarantee much lateral support. (Front-back wasn’t much of an issue if the pipe were well attached to his hand, as the top end was well anchored to the house.) It’s windy today, adding to the lateral problem.
 When I took off his shoes, I found good news: solid 3/4″ legs plus nicely screwed on foot stubs. While I wanted to avoid visible alterations, driving screws up through his shoes was fair game.
When I took off his shoes, I found good news: solid 3/4″ legs plus nicely screwed on foot stubs. While I wanted to avoid visible alterations, driving screws up through his shoes was fair game.
Drilling through his shoes was more exciting than expected. Maybe that hard layer was a PCB for the ‘Street Lights’ part of the shoes?
I found an old white melamine shelf just the right size, and with a few successful measurements, succeeded in driving 2.5″ screws thru the shelf and his shoes into solid leg wood. That provided just the lateral support I was hoping for.
An additional plus is that it provided what I thought would be a great place for a sign for the button. (Wrong.)
Enhanced candy insertion opening
 My vision (mostly used only late in the day: Laur was sitting on the porch for the daylight ToT hours) was that candy would be inserted into the pipe from a barely opened screen door. To make that more convenient, I slit one side of the pipe for 5″ or so, and heated the end halves with a heat gun until with a gloved hand I could splay it out into sort of a funnel. Did each side separately, but it worked about as planned.
My vision (mostly used only late in the day: Laur was sitting on the porch for the daylight ToT hours) was that candy would be inserted into the pipe from a barely opened screen door. To make that more convenient, I slit one side of the pipe for 5″ or so, and heated the end halves with a heat gun until with a gloved hand I could splay it out into sort of a funnel. Did each side separately, but it worked about as planned.
Robust pipe mounting
 I made a little bracket to mount the end of the pipe to a convenient screw in the door frame. The mechanical mounting part of that was fine, but then came the first of two unforeseen issues: The ‘funnel’ very effectively kept the screen door from closing. I’d done a first pass at hacking the most egregious door blocker off (with a jigsaw) in this pic. That still wasn’t enough, so the door remained ajar.
I made a little bracket to mount the end of the pipe to a convenient screw in the door frame. The mechanical mounting part of that was fine, but then came the first of two unforeseen issues: The ‘funnel’ very effectively kept the screen door from closing. I’d done a first pass at hacking the most egregious door blocker off (with a jigsaw) in this pic. That still wasn’t enough, so the door remained ajar.
Door bell
 After the pipe was nicely mounted and functional (though still blocking the door), it was time to figure out what to do about a doorbell. Looking through the boxes of switches, I came across a perfect candidate: A great big clackety momentary contact DPDT switch. The shape and layout of the switch part were completely wrong, but I really liked the button.
After the pipe was nicely mounted and functional (though still blocking the door), it was time to figure out what to do about a doorbell. Looking through the boxes of switches, I came across a perfect candidate: A great big clackety momentary contact DPDT switch. The shape and layout of the switch part were completely wrong, but I really liked the button.
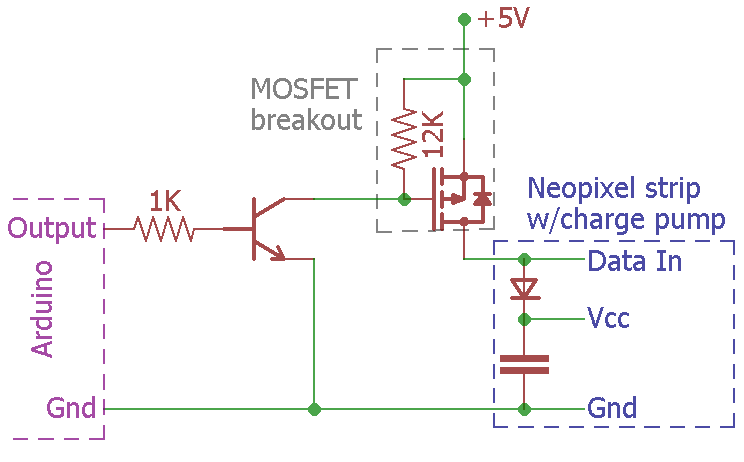
The original plan had been to put a piezo or something and a power supply inside the house connected to the button to notify us when a ToTer was there. But at some point along the way, I’d unconsciously decided rather than that to just connect to the house doorbell. It was right there, and how hard could it be to pull the doorbell button and temporarily splice a couple of wires? (Answer: harder than planned.)
A minute later, when it was time to actually figure out how to mount the switch (remember, this was a crash project!), I looked around for something solid I could build the mount from. And I spied it: a block of closed cell foam! The one I found wasn’t quite right, but with very mixed feelings, I went to the out-of-control foam/bubble wrap/etc shelves. Sure enough, there was a perfect large chunk of stuff I could cut just what I needed from. Boy, it’s a good thing I hadn’t gotten around to purging that shelf as I’ve been planning to do for a year or five!
Closed cell foam is really nice to work with for crude stuff like this. A jeweler’s saw easily cut the semi-cylindrical notch for the PVC pipe it would mount to, and an Xacto knife made quick work of cutting out the deep rectangular 0.5″ x 1.5″ hole for the clunky switch body. The hole went all the way through so the terminals rested on the pipe. Boo Boy could provide acceptable vertical support so the switch wouldn’t feel mushy.
I brought a roll of #20 solid zip cord I don’t particularly like out to the mounted tube and chopped off a piece about the right length. The tabs on the switch were very old and oxidized, but hitting them with a Dremel cutoff wheel fixed that in a few seconds. I soldered the wire to the terminals, fed it thru the hole and stuffed the switch into its final home.
 Slobbering contact cement generously all over the inside of the cutout for the tube allowed me to momentarily press the foam to the PVC pipe where I wanted it to be mounted and left just the right amount of cement on both parts. I left them to dry for a few minutes while I looked at removing the existing doorbell button.
Slobbering contact cement generously all over the inside of the cutout for the tube allowed me to momentarily press the foam to the PVC pipe where I wanted it to be mounted and left just the right amount of cement on both parts. I left them to dry for a few minutes while I looked at removing the existing doorbell button.
 Then came the second unforeseen problem with the door-frame mount of the top of the pipe: It completely obscured the doorbell button. I had to take the dumb pipe off again to get the screws out of the house button. It only took a minute or two, but grumpf.
Then came the second unforeseen problem with the door-frame mount of the top of the pipe: It completely obscured the doorbell button. I had to take the dumb pipe off again to get the screws out of the house button. It only took a minute or two, but grumpf.
With the button off, wires exposed, pipe remounted to the house, and foam and switch stuck to the pipe down at the kid end (further secured with zip ties), I wrapped the wire a few turns around the pipe and cut it to length. While the first one worked, I can’t believe I couldn’t get the second pair of wires connected with a wire nut. I tried a couple of gray, a couple of blue, added extra wire to bulk the connection up – all failed. 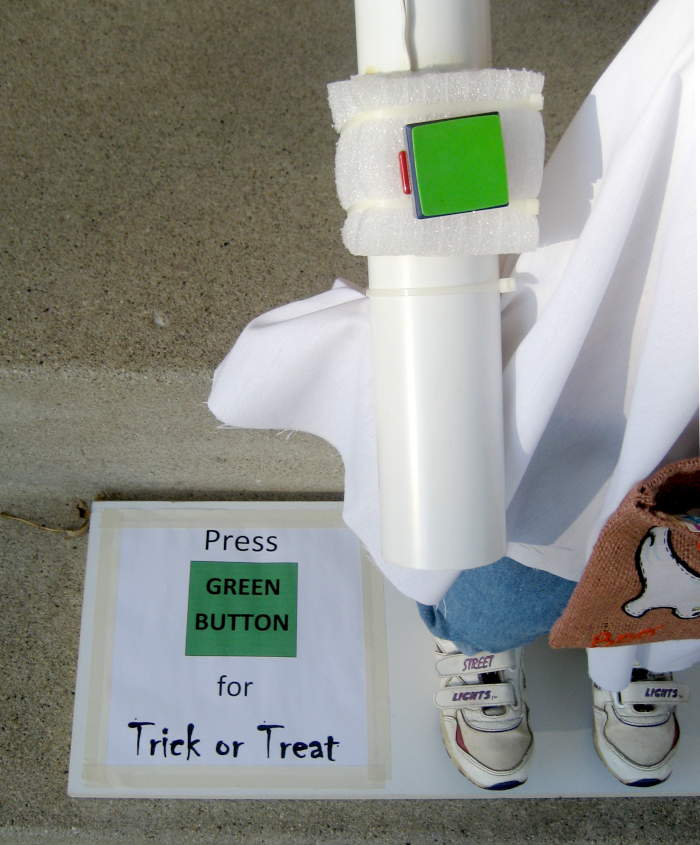 Finally found a small crimp connector and that worked. Pushed the green button, doorbell sounded, as expected. Good.
Finally found a small crimp connector and that worked. Pushed the green button, doorbell sounded, as expected. Good.
But it still needed a sign to tell ToTers to push the button. That was quick, too. Unfortunately it turned out to be sub-optimal: For too-young-to-read kids, the accompanying parent/coaches were too far behind to see the sign. Nice try.
 I’m done! Lauren sat outside for the first couple of hours, sometimes reaching up and sending candy bars down the pipe, but dropping treats whose packaging wasn’t compatible directly into their bags. She saved most of the most pipe-compatible treats, like fun-size Snickers, for after she went inside. All in all, it worked out quite well.
I’m done! Lauren sat outside for the first couple of hours, sometimes reaching up and sending candy bars down the pipe, but dropping treats whose packaging wasn’t compatible directly into their bags. She saved most of the most pipe-compatible treats, like fun-size Snickers, for after she went inside. All in all, it worked out quite well.
The LED heart ran a special Halloween program of all orange, and beating, lub-dub, with occasional minor bits of eye candy.